Methods for Causality
- mudra choudhury
- Jan 8, 2024
- 4 min read


Most of us are familiar with the saying that “correlation does not equal causation”. In science, jumping from what is a correlation to determining causal relationships is a great challenge. But did you know there are methods out there to figure out whether a relationship between two variables is causal? When I first found out about this, I was hungry to learn more.
As I have just stepped into the intricate world of causal methods in computational biology, I have little to no background knowledge. I must sheepishly admit, I turned to ChatGPT to first give me some general information, which I do recommend as a first step when learning about a topic. However, it's always important to complement such tools with a more thorough academic approach. In this post I will briefly describe what causal methods are and specific types of causal methods to answer important questions in the field.
Enjoy!
The Foundations of Causal Methods
Causal methods in computational biology aim to determine the cause-and-effect relationships between variables. For example, a study may be aiming to figure out if a gene present in cancer patients is causal to the cancer or there due to coincidence or external factors. While establishing these causative connections, they make many assumptions like having data that is controlled for confounders, and ultimately can be useful for enhancing the accuracy of predictive models. Overall, a successful causality method can be invaluable in various fields, from healthcare and economics to policymaking, impacting decision-making on multiple levels.
A Specific Type of Causal Method - Natural Experiments
The gold standard in causal analysis is controlled trials where all variables are manipulated directly. However, this is often not feasible, fast, or efficient, paving the way for natural experiments. These experiments leverage nature mimicking the circumstances you are looking for to run your causality analysis. Although they eliminate the need for researcher manipulation, a significant challenge they face is the presence of unobserved confounders, which can skew the results.
Causal Analysis in Computational Biology
**Note: Please go to Kelly et al.'s Review for a complete set of citations referred to in this post.
A review by Kelly et al. in Molecular Genetics and Genomic Medicine (2022) is particularly enlightening. It explores the crucial role of molecular networks in understanding genetic and biological mechanisms underlying various diseases. Notably, even diseases linked to specific causative genes are part of larger networks and do not act in isolation. This understanding is critical for biomedical research and developing targeted therapies.
The review also highlights the popular use of specific R software, like WGCNA, to infer undirected networks from transcriptomics data. However, the real challenge lies in constructing causal networks that differentiate directed regulatory relationships from mere associations. To this end, a range of causal inference methods have been developed using omics data.
The primary approaches used to build these causal networks include Mendelian Randomization (MR) and Bayesian networks (BN). MR operates on three key assumptions: the instrumental variables (IVs) are associated with the exposure of interest; these IVs are independent of confounders; and they affect the outcome solely through the exposure. The review discusses various MR approaches like MR-Egger, MR-PRESSO, and CAUSE, each accounting for different aspects of pleiotropic effects. The details of the method are beyond the scope of this article but check out the review paper for more details!
Bayesian Networks and Their Applications
Bayesian Networks, structured as directed acyclic graphs (DAGs), are another cornerstone in understanding causal relationships. These networks, determined via conditional independence, offer a structured approach to inferring biological relationships. Constraint-based methods and score-based methods are two primary approaches to learning these networks, with hybrid algorithms combining both. Tools like BayesNetty have made these methods more accessible, allowing for the application of algorithms like hill climbing for investigating interactions between metabolites and phenotypic data.
Addressing Computational Challenges
The review acknowledges the computational challenges in applying methods to high-dimensional datasets. It stresses the need for combining approaches to improve efficiency and accuracy. For instance, MR has been used in tandem with other methods to speed up the construction of causal networks by imposing constraints on edge directions. An innovative tool named 'findr' addresses the computational limitations of Bayesian Networks in large-scale transcriptome-wide networks, showcasing a more efficient methodology.
Finally, this paper had a very informative table of known causal methods and their characteristics:
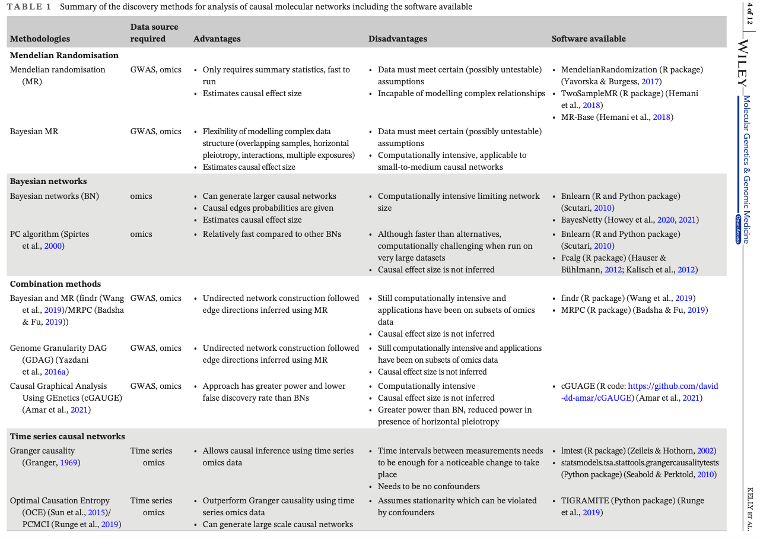
Computational Tools in Genetics
For genetics enthusiasts, the review by Richardson et al. in Cold Spring Harbor Perspectives in Medicine (2021) is very informative. It offers an overview of computational tools and databases developed for causal inference, including online tools for hypothesis generation and resources storing summary-level information for genetic markers.
Machine Learning and Causal Inference
Paola Lecca's Frontiers in Bioinformatics (2021) article emphasizes the challenges faced by machine learning in causal inference within biological networks. It underlines the fact that most machine learning methods are geared more towards predicting outcomes rather than deciphering underlying causality. This is a significant gap in molecular biology, where computational methods have been actively sought to infer biological networks since the early 2000s.
I hope I can read more about this topic in general. I acknowledge that this subject area, particularly the intersection of machine learning and causal inference, is one I need to delve deeper into, given my limited familiarity with it.
Integrating Prior Knowledge and Causal Methods
An intriguing perspective is presented by Barsi and Szalai in Patterns (2021), advocating for the integration of prior knowledge with causal methods. This approach combines knowledge-driven methodologies with data-driven machine learning models to identify more accurate causal relationships.
Takeaways:
Thanks for dipping your toes into causality with me. Here are some of my takeaways so far:
Causal methods are crucial for comprehending relationships between biological variables beyond mere associations, playing a pivotal role in identifying therapeutic targets. I'm keen to further explore these methods for a better grasp of their practical application.
Current challenges in this field include the need for precise data devoid of confounders, the disagreement among various methods, and the high computational demands limiting these methods to smaller datasets.
The quest for more accurate causal reasoning tools may lie in merging established knowledge with data-driven machine learning techniques.
References:
Barsi S, Szalai B, Modeling in systems biology: Causal understanding before prediction? Patterns (2021) DOI: https://doi.org/10.1016/j.patter.2021.100280.
Kelly, J., Berzuini, C., Keavney, B., Tomaszewski, M., & Guo, H. A review of causal discovery methods for molecular network analysis. Molecular Genetics and Genomic Medicine (2022). DOI: https://doi.org/10.1002/mgg3.2055
Lecca P. Machine Learning for Causal Inference in Biological Networks: Perspectives of This Challenge. Frontiers in Bioinformatics (2021). DOI: 10.3389/fbinf.2021.746712
Richardson TG, Zheng J, Gaunt TR. Computational Tools for Causal Inference in Genetics. Cold Spring Harb Perspect Med. (2021) DOI: 10.1101/cshperspect.a039248.



Comments